Summary of Hoplite
⚠ 转载请注明出处:Maintainer: MinelHuang,更新日期:Dec.18 2021

本作品由 MinelHuang 采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可,在进行使用或分享前请查看权限要求。若发现侵权行为,会采取法律手段维护作者正当合法权益,谢谢配合。
目录
1. 前言
参考资料:Hoplite: efficient and fault-tolerant collective communication for task-based distributed systems. 2021. SIGCOMM
场景和Problems
该论文的应用场景为,task-based runtime distributed framework。与传统的task-based framework或data-based framework不同的是,runtime framework会在runtime中创建新的任务,并schedule某个worker去运行该任务。那么对于communication这一层而言,如何在runtime中运行collective collective communication如all-reduce是一个问题。
传统的collective communication如OpenMPI, MPICH, Horovod, Gloo, NCCl等都需要在runtime之前先得知communication pattern,即app需要指出参与的workers会在runtime中如何通信。但在runtime framework中,对于新的任务我们是没法提前得知其会被部署在哪个worker上,也就无法得知该如何collective communication。
所以,Hoplite允许参与者动态的运行collective communication,其计算data transfer schedule于任务或对象产生/到来时,并使用fine-grained pipelining运行low-latency data transfer scheduling。
本博客将从AllReduce开始,逐步介绍为何需要在machine learning中使用该算法,allreduce被应用在哪个组件中。最后本文将介绍Hoplite对原有工作的优化。
2. AllReduce
AllReduce概述
参考资料:腾讯机智团队分享--AllReduce算法的前世今生
在分布式机器学习中,通常数据是分布在各个worker上的,即每个worker持有一部分的data partition。通常在一次迭代中,每个worker通过local computing得到gradients信息,而后需要使用所有的gradients来更新模型weights。
那么由哪台worker收集所有的gradients而更新weights呢,一种思想如下图: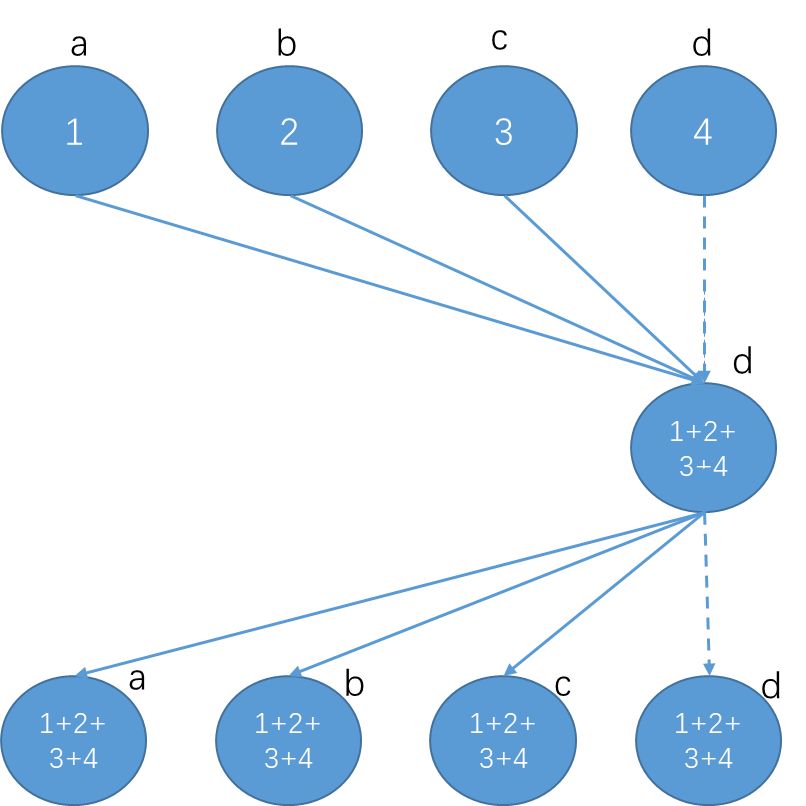
我们可以通过Reduce + Broadcast的方法来实现,也即parameter server架构。我们现在尝试使用数学来定义上述过程的时间开销。设`a`代表两个通信节点之间的latency,`S`代表每个worker上的数据量,`B`代表带宽,`C`代表处理一个byte数据所耗费的时间,`N`代表worker总数。
故在parameter server架构下,所需的总时间为`2*(\alpha +S/B) + N*S*C`
在PS架构中我们发现,PS节点的带宽成为瓶颈,并且仅使用了PS节点的算力,我们希望通过一种手段能同时优化communication & computation,即让节点间的通信开销负载均衡,并在这一过程中能动用更多的算力。AllReduce实现了这一目标,下面我们以Ring AllReduce为例来阐述其如何实现的。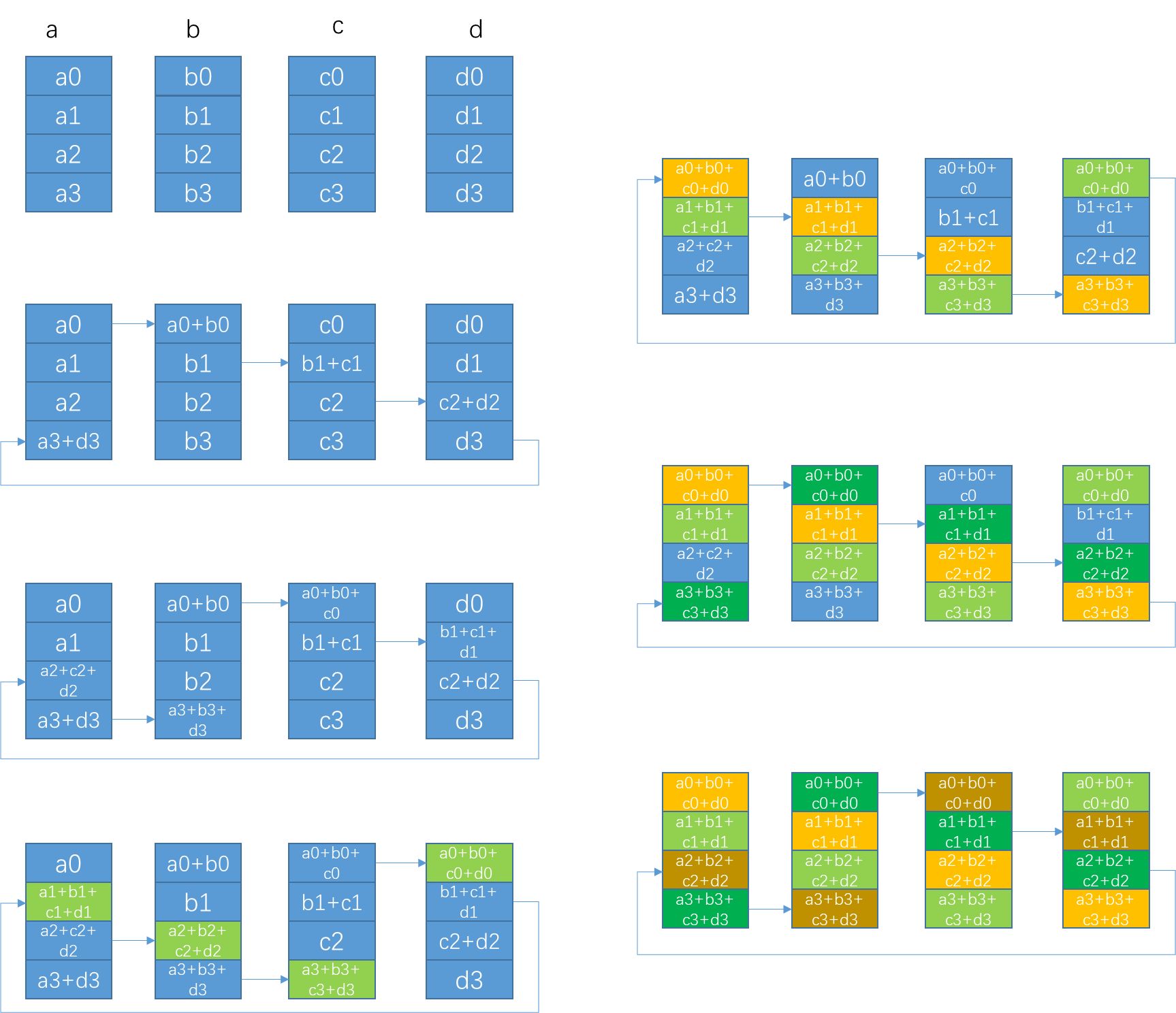
AllReduce算法分为两步,第一步为让每一个worker都得到1/N的数据块,称为scatter-reduce,每一步通信耗时`\alpha + S/(NB)`,计算耗时`(S/N)*C`,共`N-1`步。该步对应上图左侧部分。
第二步是使所有的worker上每一个`1/N`块都完整,称为allgather,每一步的通信耗时`\alpha + S/(NB)`,没有计算开销。该步对应上图右侧部分。
那么,整体的耗时可以表示为,`2*(N-1)*[\alpha + S/(NB)] + (N-1)*[(S/N) * C]`。对比于Parameter Server模型,每一步一个worker仅会发送一次、接受一次`S/N`大小的数据块,于是我们可以说单步通信开销减少,并且负载均衡;在计算部分由于所有worker都参与了计算,故计算时间开销降低了`N`倍;甚至该方法节省了每台worker上的内存开销。后面笔者会描述,在Machine Learning领域,allreduce的用途和研究点。
AllReduce in Machine Learning
参考资料:Bringing HPC Techniques to Deep Learning
假设我们使用data parallel stochastic gradient descent,其过程是,数据分布在各个worker上,每个worker计算出gradients后,与其他workers交换,最后使用所有的gradients更新本地模型。在这一情景中,数据是distributed,而每个worker持有全部的模型信息。首先明确的是,我们使用很庞大的模型,即parameters的数量庞大。这样导致每个worker产生的gradients数量也很庞大,由此导致较长的communication costs。我们尝试着,能否使用ring allreduce方式,同时达到distributed computation、降低单步communication cost和节省GPU空间三个目的。
在DNN反向传播中,每一层的weight更新都需要对该层的梯度信息进行求和,显然在分布式SGD中梯度信息是分布在各个worker上的。在这里我们可以使用allreduce来降低该部分的时间开销。
3. Horovod
参考资料:Horovod: fast and easy distributed deep learning in TensorFlow. 2018. arXiv
场景和Problem
Horovod的应用场景为deep learning,目前deep learning的模型规模和数据集规模增长日益庞大,故单块GPU的训练时间过长。用户开始考虑使用分布式GPU来承载庞大的数据,其一般使用方式如下:
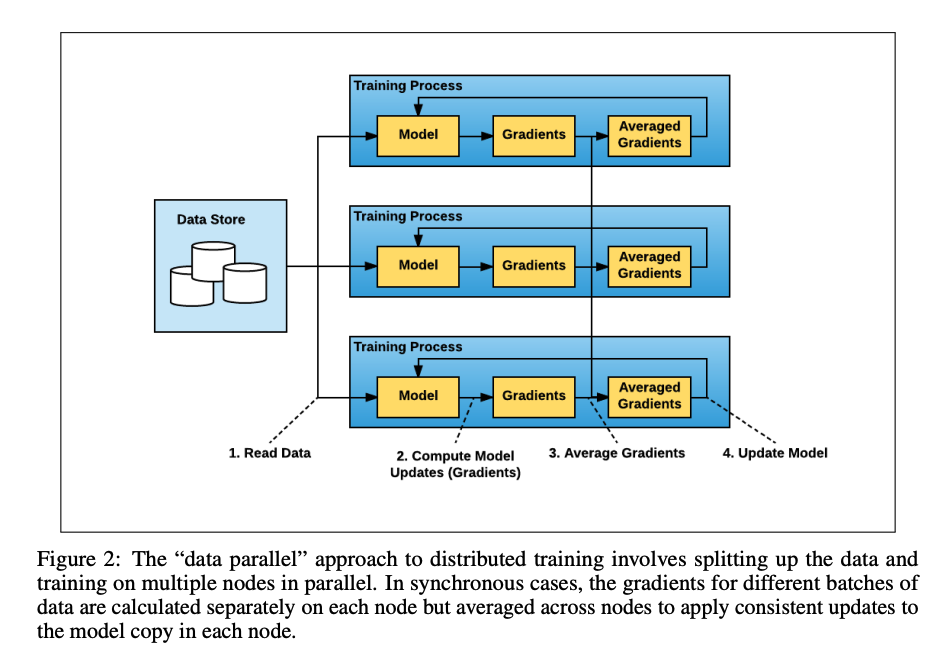
数据分布式的存放在不同的工作节点中,即data parallel方式,分布式的过程称为data partition。worker在本地计算gradients,再通过相互交换数据完成aggregate gradients过程,最后更新模型。
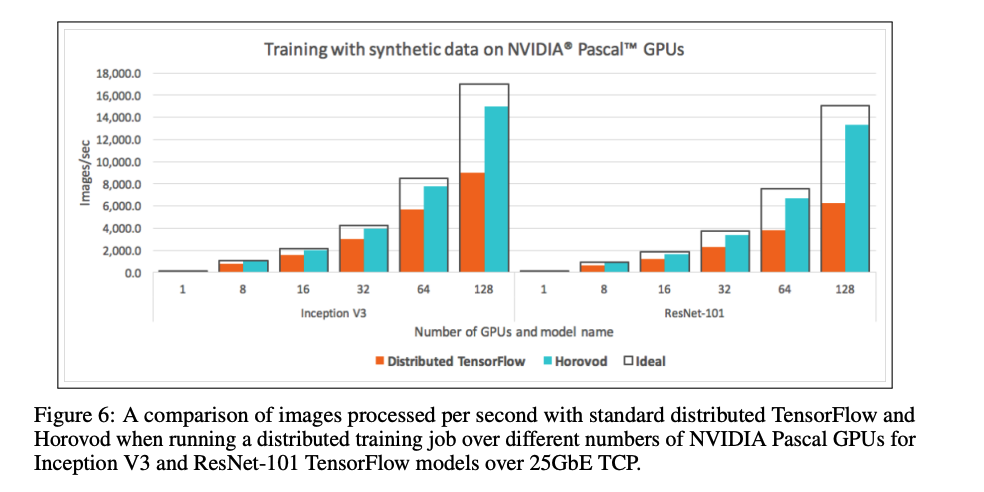
在Tensorflow distributed中,测试发现分布式计算的性能较差,测试效果如下图:
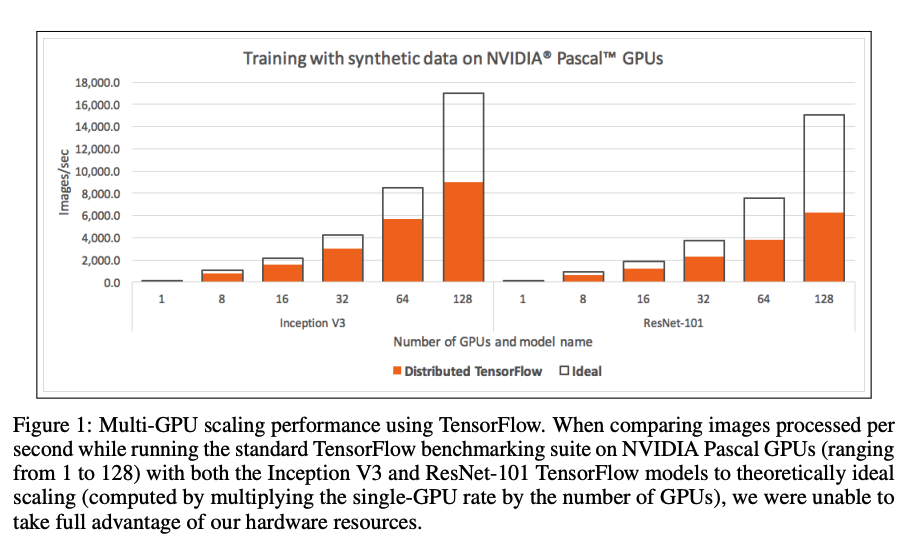
可以看到,随着GPU规模变大,其实际性能小于使用data-parallelism的方法进行分布式的ideal性能。这是因为几乎有一半的时间开销为通信开销。一部分的开销在上节有提到,为Parameter Server架构带来的通信和计算瓶颈;第二部分为tensorflow server交互带来的开销。回想下tensorflow分布式架构,其server需要根据用户代码形成dataflow,而后place任务至不同的worker节点,开始execution。这一过程涉及code reconsturction,用于重新构建在workers上运行的实际代码,也会带来一定的时间损耗。
Solution
Horovod采用Baidu提出的ring allreduce算法来降低multi-GPU中的gradient aggregated通信开销。梯度聚合在tensorflow server上(或dataflow中)被表示为tensor fusion。展开来说是,gradient aggregated函数的输入为gradients,在dataflow中gradients是由多个tensor组成的,故在有tensor fusion的过程中不再像以前一样将所有所需的tensors流入一个worker,而是让tensors所在workers group运行ring allreduce算法。这样一来,allreduce便结合进tensorflow中了。在采用allreduce后,对distributed tensorflow达到了约65%的提升,如下图:
3. Hoplite
参考资料:Hoplite: Efficient and Fault-Tolerant Collective Communication for Task-Based Distributed Systems. 2021. SIGCOMM
为什么要使用AllReduce
首先,我们依旧需要分析一下在动态tasks场景下为何需要allreduce,或者说allreduce解决的是哪一部分的瓶颈。Hoplite是对Ray系统的一个优化组件,故我们同样在actor-based + 强化学习的场景中讨论。
动态task-based系统常用于开发包含异步、动态计算、动态通信组件的分布式应用,其中动态指无法在runtime前预测并schedule的functions。一个典型的动态task模型为:a caller动态的创建了task A和task B,task A立刻返回一个future object作为task B的输入,在task A运行结束后,task B立刻开始执行。Task-based system负责的是,为task A和task B分配workers以执行,并传递task A的运行结果至task B;第二点是负责fault tolerance,即若task A或B出现崩溃,则立刻创建新的任务来保证程序正常完成。
显然,task A和task B之间存在data transfer和data computation。在强化学习场景中,task A和B之间的关系可以类比成training和simulator间的关系。Training动态创建了simulators,根据当前policy产生actions,并将其输入至simulators;simulators得到rewards之后再返回给training。Training任务最后再根据rewards计算loss和gradient,完成一次迭代的模型更新。
在这里,与上一节deep learning中相同,gradients数据量庞大(分布在各worker上)并需要进行聚合操作,当然我们希望能否使用allreduce的方式降低此部的开销。然而由于training function是被动态创建的,我们并不清楚参与此次allreduce的workers/tasks/data partitions是哪些,也即并不能在runtime前得知communication pattern。这导致allreduce无法运行,即我们没法构建类似ring allreduce那样的通信环。除非,我们可以在runtime中完成构建communication pattern这件事。一种可行的方法是将所有的参与方同步,经同步后当然可以构建出communication pattern,但是这样一来部分progress显然会陷入idle状态,对于一些异步应用如distributed RL的性能影响是致命的。
第二个问题在于,如果在allreduce过程中发生错误怎么办,显然在某一步,例如allgather中,一个node出现failure会使得所有参与allreduce的节点都得不到完整信息,一个高效的fault tolerance方式也是必须的。
Hoplite Contributions
我们需要完成的是,在runtime中异步的完成efficient and fault-tolerant collective communication layer。在这里,输入的data partitions是动态的,所以该layer可以拆分为对每一个arrive object进行data transfer schedule,并设计一个pipeline使得即使只有一部分的participants are ready,依旧可以开始collective communication。
其二是在错误发生后,Hoplite可以动态的调整data transfer schedule以降低failed task对整体结果的影响。该fault-tolerance方法允许live tasks make progress,也允许failed task rejoins。
Design
首先我们先明确在Ray中,reduce的瓶颈在何处。

上图为使用Ray异步的训练policy过程。何为异步?(a)中程序表示,对所有agent下发上一次迭代更新后的policy,每个agent各自计算gradients。对于training process,只要有gradient产生便立即更新policy,直至batchsize,而后向所有agents下发新的policy。这样做我们发现,快的agent在完成一次rollout(即产生gradients)后不需要等待慢的agents完成,便可以开始下一轮rollout,即异步操作。
(b)中可以看到对gradients显然要进行reduce操作,即aggregation。对于training process而言,其既需要接受来自agents的gradients,又需要做reduce运算,最后还要向所有agents下发policy,显然当model较大时会产生通信瓶颈/计算瓶颈,故在此我们希望使用allreduce。
对于设计allreduce,我们需要考虑两个challenges。第一为在Ray中所有的任务都是动态创建的,也即我们不知道参与此次allreduce的参与方(worker/actor产生的objects)准备好的时间和位置,即不知道communication pattern;并且我们也不能等待所有参与方准备好了再开始,因为这样便退化为与spark等相同的BSP模型(强一致性的同步),对效率有很大的损耗。第二点是与上文讲的相同,需要设计fault-tolerance。
Workflow
该节主要讲述Hoplite包含哪些组件,以及和task-based system间的关系。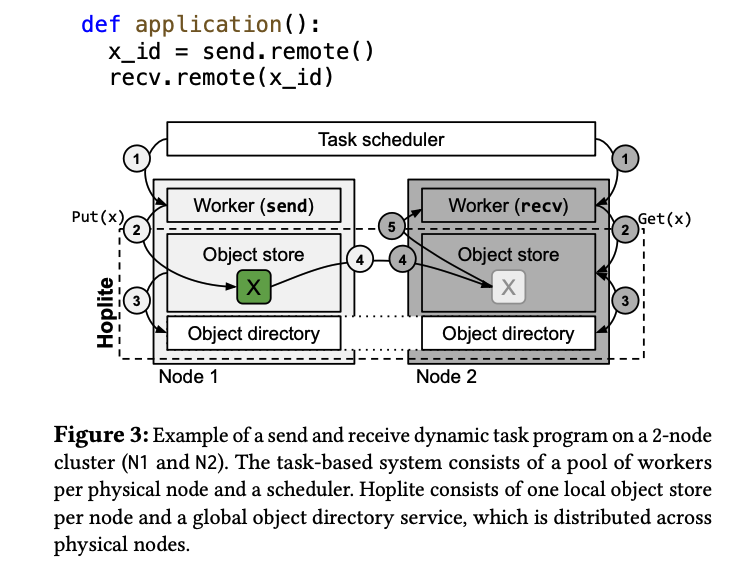
如上图,Hoplite包含两个重要组件:Object store & Object directory。对于collective communication而言,重点在于收发两方。对于发送方,一旦某个object被准备好,则将其拷贝到local object store中,并在object directory上登记此Object ID;对于接收方,其在code上可以得知所需的future object,但receiver想要开始执行必须要等待接受到所有的future object,故在sender还未准备好future obect前,receiver只能block.
我们的目的是完成allreduce操作,故设立object directory来记录当前已经准备好的object。而后当一个worker需要执行allreduce时(会给出allreduce所需的future object),Hoplite可以根据current object directory来判断参与此次allreduce的输入object是否准备好了。而后需要考虑的是,如何使用部分object开启collective communication。所以我们看到,Hoplite是通过动态调整allreduce中的data transfer部分(也叫data transfer schedule)来实现动态allreduce的。至于是否要使用allreduce,allreduce前的data partition方式都不属于Hoplite的管辖范围。当然对于reduce等操作也同样可以使用Hoplite,故在论文中,Hoplite的服务对象为collective communication。
关于Hoplite具体的优化方法(pipeline、receiver-based collective operation、fault-tolerance)请自行阅读论文,笔者会在总结中给出solution的main ideas。
总结
Hoplite的核心思想是,如何动态的调整data transfer来适应动态任务环境。对于collective communication如broadcast、reduce、allreduce而言,动态环境指的是参与此次reduce操作的数据object可能是准备好了,可能没有准备好(future),我们希望的是能动态的调整object间的data transfer依赖关系,从而高效的实现collective operation。
那么第一点,在两方情景下(sender+receiver)下的通信如何高效?Hoplite提供了Object Directory Service来告知object的准备情况,并使用pipeline来高效的完成data transfer(sender向ODS中copy object的同时便开始和receiver之间的data transfer,这样用network transfer掩盖了copy object from node to OBS的时间)。
第二点是,如何动态的调整data transfer以实现collective operation。Hoplite提供了broadcast和reduce方法,其中broadcast参考P2P传输方式,如下图,OBS记录object当前的拷贝情况,并通过调整data transfer关系来实现P2P传输。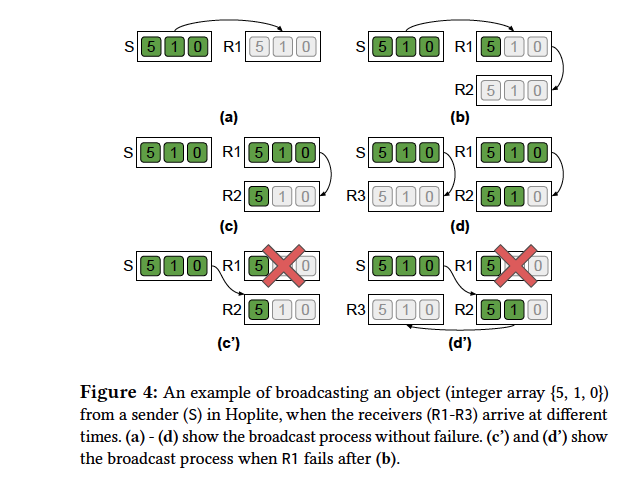
Reduce操作较为复杂些,Hoplite采用tree-structured reduce algorithm为所有的参与方建立树模型,并提供scheduler来优化树的深度(使得communication cost最优),如下图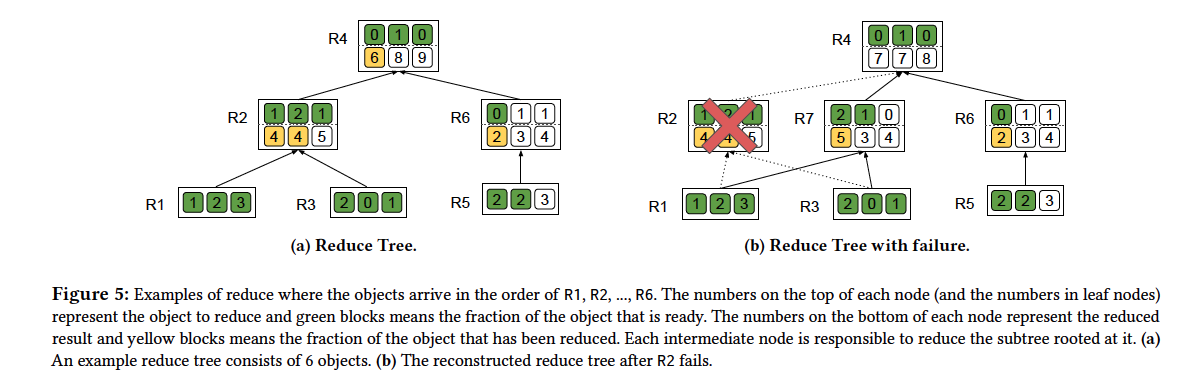
最后,为了与其他工作做区别,笔者将high-level的概述下Hoplite到底是对分布式计算的哪一方面做了贡献。分布式系统是为一个task中的所有functions分配worker以运行,Ray做到了在runtime中为新的function分配worker。那么对于一个function而言,包含数据输入(data partition)、计算、数据输出三个过程,Hoplite做到的是让输入输出中包含的data transfer过程更加高效。而并没有定义一个runtime function的输入数据、输出数据该如何分片、或者是由哪些节点进行计算。所以,Hoplite必须被告知输入输出数据的位置,以及哪些节点参与此function的运算。
同样的,Ray也没有对上述两点进行schedule,其关注的是对于app开发人员提供一个动态的分布式编程接口,而后根据“哪个worker有足够的资源就在哪运行”的原则为新的function/task分配workers。所以笔者认为,可以根据app的需求设计schedule方法,继续进一步的优化分布式task执行效率。
END